ANÁLISIS EXPLORATORIO DE DATOS EN PLANEACIÓN DE DEMANDA
¿QUE ES EL ANÁLISIS EXPLORATORIO DE DATOS?
Los profesionales de Planeación de Demanda o Demand Planners utilizan el análisis exploratorio de datos (Exploratory Data Analysis) con el fin de analizar e investigar conjuntos de datos y resumir sus principales características, a menudo empleando métodos de visualización de datos. El EDA ayuda a determinar la mejor manera de manipular las fuentes de datos para obtener las respuestas que necesita, lo que facilita a los planeadores de demanda descubrir patrones, detectar anomalías, probar una hipótesis o comprobar supuestos.
El EDA se usa principalmente para ver qué pueden revelar los datos más allá de la tarea formal de modelado o de prueba de hipótesis y proporciona una mejor comprensión de las variables del conjunto de datos y las relaciones entre ellas. También puede ayudar a determinar si las técnicas estadísticas que está implementando para el análisis de datos son apropiadas. Desarrollado originalmente por el matemático estadounidense John Tukey en los 70, las técnicas de EDA siguen siendo un método ampliamente utilizado en el proceso de descubrimiento de datos hoy en día.
.
Mediante el proceso del EDA, estamos tratando de encontrar varios aspectos relevantes en demanda como por ejemplo:
- Conocer la estructura y distribución de los datos
- Encontrar las relaciones entre las variables explicatorias
- Encontrar la relación que tienen las variables explicatorias con la variable respuesta
- Encontrar posibles errores, datos atípicos (outliers) y anomalías en los datos
- Identificar patrones de comportamiento
- Refinar o confirmar nuestras hipótesis
- Generar nuevas preguntas sobre los datos que tenemos
.
OBJETIVO DEL ANÁLISIS EXPLORATORIO DE DATOS
El propósito principal del EDA es ayudar a estudiar los datos antes de hacer cualquier supuesto. Puede ayudar a identificar errores obvios, así como comprender mejor los patrones dentro de los datos, detectar valores atípicos o eventos anómalos, y encontrar relaciones interesantes entre las variables.
Los profesionales de planeación de demanda pueden utilizar un análisis exploratorio para garantizar que los resultados que producen son válidos y aplicables a los resultados y objetivos empresariales deseados., como el cumplimiento o no del presupuesto, expectativas de crecimiento o decrecimiento, entro otros. El EDA también ayuda a los stakeholders al confirmar que están haciendo las preguntas correctas. El EDA puede ayudar a responder preguntas acerca de desviaciones estándar, variables categóricas e intervalos de confianza.
No existe como tal una técnica formal que nos indique como llevar a cabo este tipo de análisis, mas bien depende de lo que vayamos encontrando en los datos, así como la experiencia y el conocimiento especifico del campo que tengamos, el análisis exploratorio de datos es como un trabajo detectivesco, se buscan claves y pistas que puedan conducir a la identificación de las posibles causas de origen del problema que se intenta resolver. Se exploran las variables de una en una, luego de dos en dos, y luego muchas variables a la vez, como el EDA implica explorar, podemos decir que es un proceso iterativo. .
TIPOS DE ANÁLISIS EXPLORATORIO DE DATOS
Existe literatura extensa acerca de las diferentes tipos de EDA, pero de un modo practico lo podemos resumir en 4 tipos:
- Numérico Univariante
- Grafíco Univariante
- Numérico Multivariante
- Grafíco Multivariente
1. Numérico Univariante
Esta es la forma más simple de análisis de datos, donde los datos analizados consisten en una sola variable, es el tipo de EDA mas básico y usado por los profesionales de Planeación de Demanda debido que es una sola variable la de nuestro interés (Demanda), en este análisis no se ocupa de las causas o relaciones. El objetivo principal del análisis univariante es describir los datos e identificar los patrones que existen en ellos, a continuación los descriptores univariantes mas comunes son:
- Número de observaciones
- Máximo
- Mínimo
- Rango
- Tendencia
- Desviación estándar
- Media o promedio
- Mediana
- Moda
- Coeficiente de variación
- Simetría
- Curtosis
- Funcíon de autocorrelación
2. Gráfico Univariante
Los métodos numéricos no proporcionan una imagen completa de los datos, por lo tanto, se requieren métodos gráficos. Los tipos comunes de gráficos univariantes incluyen:
- Diagrama de Líneas, Los gráficos de líneas se utilizan para mostrar el valor cuantitativo en un intervalo de tiempo continuo. Se usa con mayor frecuencia para mostrar tendencias y relaciones (cuando se agrupan con otras líneas). Los gráficos de línea también ayudan a dar un «panorama general» en un intervalo, para ver cómo se ha desarrollado durante ese período.
.
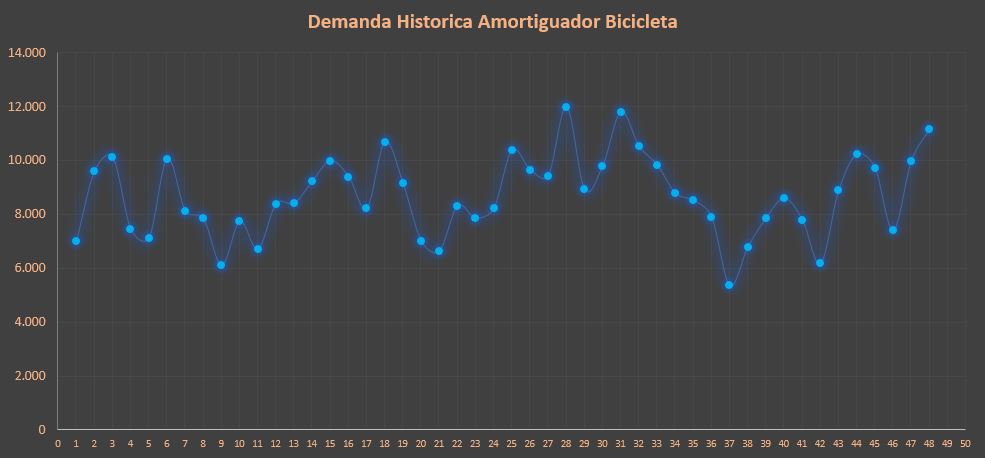
Gráfico 1. Diagrama de Linea
.
- Histogramas, diagramas de barras en los que cada barra representa la frecuencia (recuento) o la proporción (recuento/recuento total) de casos para un rango de valores.
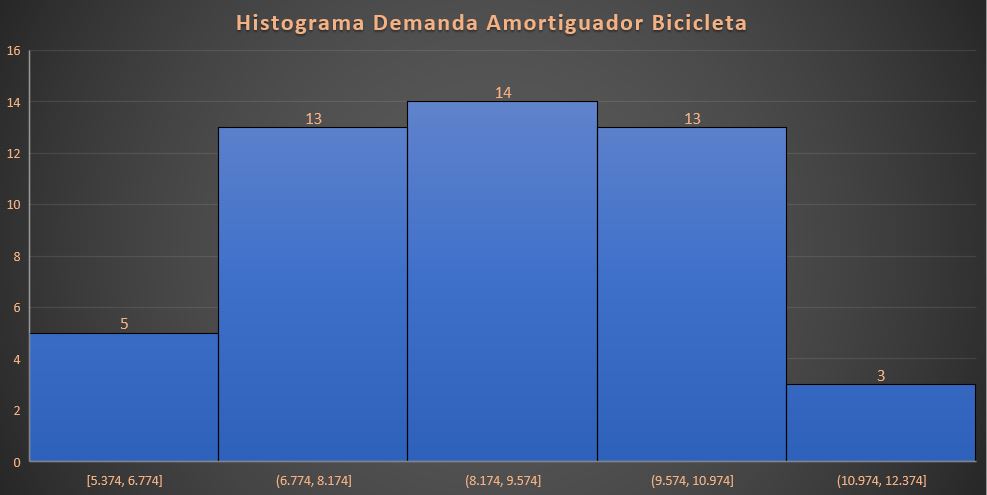
Gráfico 2. Histograma
.
- Diagrama de Cajas – Bigotes (boxplots o box and whiskers) son una presentación visual que describe varias características importantes, al mismo tiempo, tales como la dispersión y simetría. Se representan gráficamente el resumen de seis números dentro de los datos, el mínimo, primer cuartil, mediana, media, tercer cuartil y máximo, también ayuda a identificar valores atípicos (outliers).
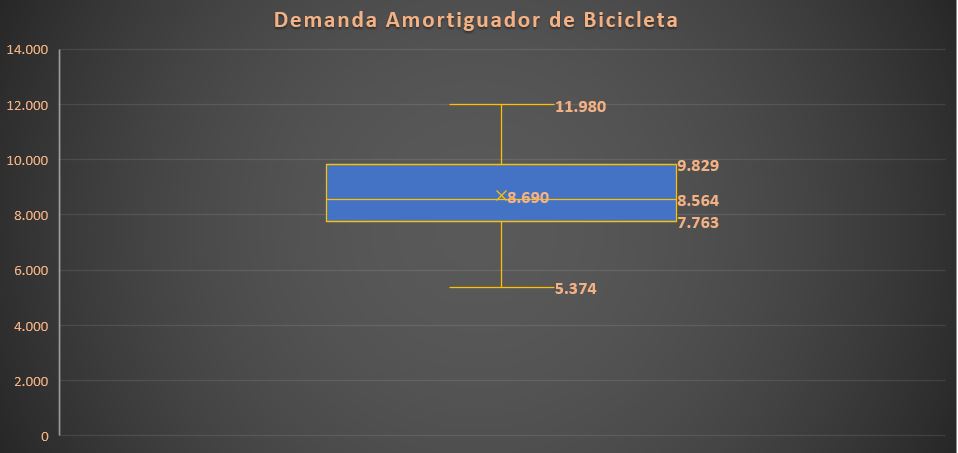
.Gráfico 3. Diagrama de Cajas – Bigotes
.
3. Numérico Multivariante
Se obtienen datos multivariantes de más de una variable. Las técnicas de EDA no gráficas y multivariantes generalmente muestran la relación entre dos o más variables de los datos a través de la tabulación cruzada o las estadísticas, el estadístico mas usado en técnicas multivariantes es el coeficiente de correlación.
.
4. Gráfico Multivariante
Los datos multivariantes utilizan gráficos para mostrar relaciones entre dos o más conjuntos de datos. El gráfico más utilizado es un diagrama de barras agrupadas o un gráfico de barras donde cada grupo representa un nivel de una de las variables y cada barra dentro de un grupo representa los niveles de la otra variable.
Muchos procedimientos estadísticos en planeación de demanda exigen una serie de requisitos según de cual se trate, pero en términos sencillos, los podemos resumir así:
- Homogeneidad
- Independencia
- Normalidad
.
HOMOGENEIDAD
En toda serie histórica de datos (Serie de tiempo) es conveniente revisar que tan homogéneos son los datos, en el análisis de series de tiempo, nos interesa la “estabilidad” de la demanda en relación al tiempo. Debemos chequear la presencia de valores extremos Máximo y Mínimo, este tipo de datos reciben el nombre de datos influyentes o atípicos (outliers en ingles), se llaman influyentes por dos motivos, 1) porque llaman mucho la atención de los interesados al responder la pregunta de cuanto ha sido la mayor venta o cuanto fue la menor venta o en que periodos se han presentados los dos eventos anteriormente mencionados y 2) porque influyen de manera positiva o negativa en los resultados de estimación de la demanda.
.
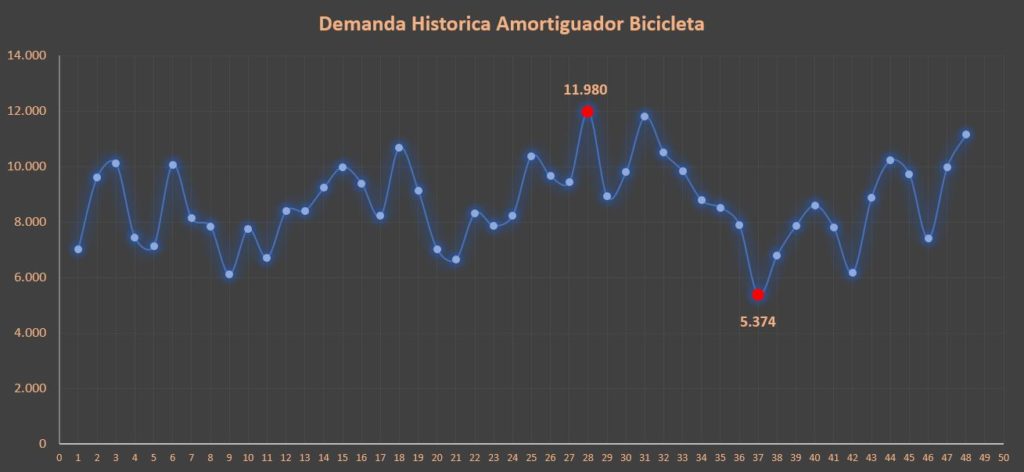
Grafico 1. Valores Máximo – Mínimo
.
Contando con los datos máximos y mínimos podemos identificar el Rango (máximo – mínimo), el rango nos permite tener una idea de la dispersión de los datos, cuanto mayor es el rango mayor será la dispersión de los datos (sin considerar la afectación por parte de los outliers), en otras palabras nos da una idea del espacio en el cual se moverá la demanda.
.
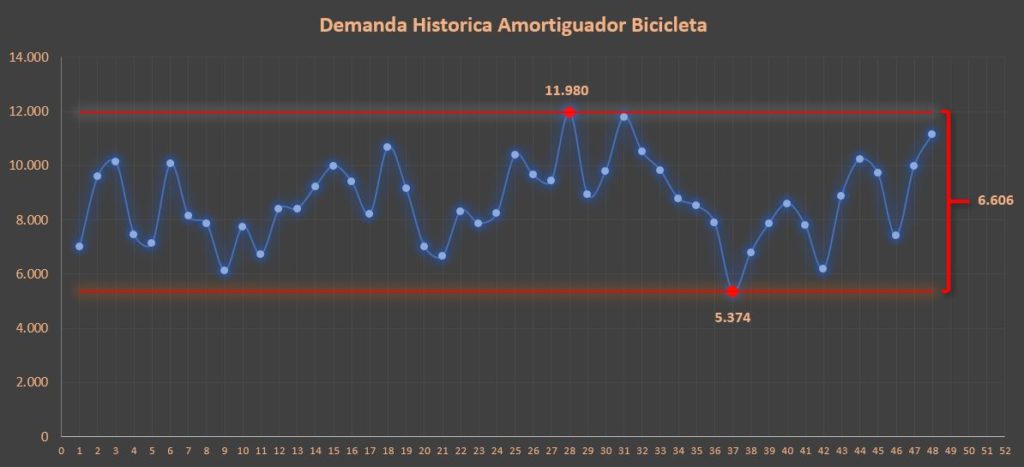
Grafico 2. Rango
.
¿Porqué nos importa en planeación de demanda la HOMOGENEIDAD?
El objetivo del análisis y modelado de series de tiempo es usualmente la construcción de modelos de pronósticos que ayuden a estimar la demanda con un alto grado de asertividad con el fin de anticipar el abastecimiento tanto de producto terminado como el de materiales y materia prima. Entonces, ¿Cómo podemos generar estos pronósticos utilizando un modelo con parámetros variables en el tiempo? ¿Cuánta confianza podemos poner en esos pronósticos? ¿El pronóstico es robusto? ¿el pronóstico interpretó el patrón de comportamiento?.
Para resolver las preguntas anteriores es relevante conocer lo opuesto a la homogeneidad y que en la mayoría de las ocasiones es lo que representa a la demanda real, me refiero a la HETEROGENEIDAD.
¿Qué factores afectan la HOMOGENEIDAD en planeación de demanda?
- La demanda está evolucionando con el pasar del tiempo. En este caso, tratar de ajustar un modelo de pronóstico con valores de parámetros fijos no sería óptimo, a pesar de nuestros mejores esfuerzos. Necesitamos examinar técnicas avanzadas de modelado para interpretar el patrón de comportamiento de la serie histórica de la demanda. Esto se encuentra fuera del alcance del EDA por lo que lo trataremos en otro post (modelos de pronósticos)
- La demanda posee algún grado de tendencia o estacionalidad.
- La demanda ha sufrido cambios estructurales puntuales debido a eventos exógenos, como un plan de oferta y promoción, descuentos, aumento o disminución de precios, aprobación y aplicación de nuevas leyes relevantes o un importante desarrollo en el proceso mismo.
.
INDEPENDENCIA
En el análisis de series de tiempo, podemos decir que dos sucesos son independientes entre sí, si la ocurrencia de uno de ellos no afecta para nada a la ocurrencia del otro, ejemplo: el evento de la temperatura de una región y la demanda de una golosina son “independientes”, el hecho de que en una región sea mas calurosa o mas fría no va influir de manera considerada los niveles de venta de una golosina y viceversa.
Para que dos sucesos sean independientes es necesario verificar al menos una de las siguientes condiciones:
- P (B/A) = P (B) es decir, que la probabilidad de que se de el suceso B, condicionada a que previamente se haya dado el suceso A, es exactamente igual a la probabilidad de B.
- P (A/B) = P (A) es decir, que la probabilidad de que se de el suceso A, condicionada a que previamente se haya dado el suceso B, es exactamente igual a la probabilidad de A.
- P (A L B) = P (A) * P (B) es decir, que la probabilidad de que se de el suceso conjunto A y B es exactamente igual a la probabilidad del suceso A multiplicada por la probabilidad del suceso B.
Algunos ejemplos de sucesos que generan “dependencia” en la demanda y que desde planeación de demanda deben ser bien analizados son:
- Inversión en publicidad, estadísticamente se encuentra demostrado que a mayor nivel de inversión en medios publicitarios mayor será la demanda. generando algún grado de dependencia.
- Precio del Dólar, este suceso afectará de manera considerable la demanda, a mayor precio del dólar, encarecerá el valor del producto ocasionando que se disminuyan las ventas y viceversa.
- Nivel de desempleo, a mayor nivel de desempleo, menor es el poder adquisitivo de las personas, por tal motivo este suceso puede crear algún grado de dependencia en la demanda.
- Nivel de temperatura, en algunos casos para algunos productos, el suceso del nivel de temperatura puede afectar la demanda de un producto, ejemplo, a mayor nivel de temperatura puede aumentar la demanda de bebidas refrescantes o helados.
.
NORMALIDAD
A fin de comprender e interpretar de manera adecuada una serie de tiempo (demanda histórica), se requiere conocer una de las más importantes distribuciones de probabilidad denominada distribución normal. Las características básicas de ella se tratan a continuación.
Una distribución normal representa la forma en la que se distribuyen en la naturaleza los diversos valores numéricos de las variables continuas, la normalidad esta basada en un concepto invariado o aislado con enfoque estadístico generado por una serie de valores u observaciones de una sola variable (univariables) como pueden ser estatura, peso, en nuestro caso una serie de tiempo.
Para delimitar la NORMALIDAD se requiere de un método matemático que defina los valores numéricos que dividan la zona de normalidad y anormalidad en nuestra serie de tiempo.
Características de la NORMALIDAD en una serie de tiempo
- Está determinada por dos parámetros, LA MEDIA y LA DESVIACIÓN ESTANDAR.
- Es SIMETRICA en torno a la media, es decir, el 50% de los datos se encuentran a la derecha y el otro 50% de los datos se encuentran a la izquierda.
- MEDIA, MEDIANA y MODA, son iguales, sin embargo es poco probable que en una serie de tiempo de la demanda de un producto presente MODA por tal motivo no podemos ser muy exigentes con esta característica al momento de descartar NORMALIDAD.
Podemos decir que una serie de tiempo presenta NORMALIDAD cuando el 95,5% de las observaciones se encuentran dentro del intervalo de la MEDIA +/- 2 DESVIACIONES ESTANDAR y tan solo un 4,5% se encuentran fuera de ese intervalo.
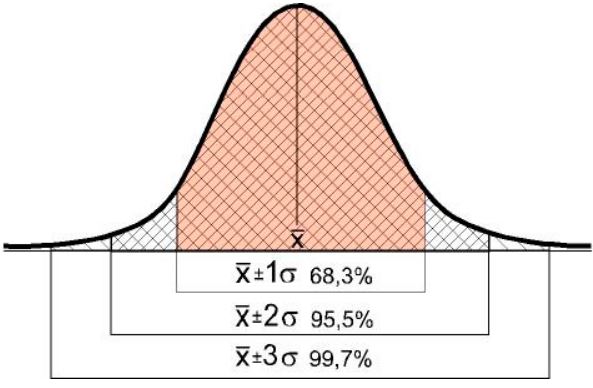
Grafico 3. Distribución Normalidad
Acerca de JOSÉ ANDRÉS ROSAS

correo electroníco: joserosassoluciones@hotmail.com

GENERADORES DE INVENTARIOS
Hoy en día en las empresas es común encontrar el panorama donde los niveles de inventario son superiores a los que requiere su actividad comercial y productiva. Esta situación perjudica notablemente la disponibilidad de capital trabajo (efectivo) recurriendo a prestamos bancarios para solventar la nómina, el pago a proveedores u otras obligaciones financieras, sin dejar de lado los inconvenientes que ocasionan en la ocupación de los centros de almacenamiento y su administración.
La necesidad de mantener cierto nivel de inventario y si ese nivel es el adecuado o no dependerá en gran medida del tipo de empresa y también de la clase de producto que comercialice. Por ejemplo, una empresa de consumo masivo que comercialice un producto de cuidado personal deberá mantener niveles más altos de inventarios en comparación a una empresa que comercialice un producto perecedero (de corta vida útil) como las carnes frías.
Es importante para los administradores de inventarios conocer cuales variables involucradas dentro de la cadena de suministros son las que de manera natural obligan a mantener inventario con el fin de garantizar la continuidad en el abastecimiento y cuales otras variables no obligatorias de cumplimiento pero que por la actividad u operación del negocio me llevan a adquirir inventarios innecesarios.
Para comprender este aspecto he dividido a los GENERADORES DE INVENTARIOS en dos grupos:
GENERADOR NATURAL
Los GENERADORES NATURALES de inventario son aquellas variables que por la dinámica de abastecimiento y de comercialización nos llevan si o si (obligan) a mantener inventario, de no ser así, se vería afectada la continuidad del abastecimiento tanto por parte del proveedor como de la empresa hacia sus clientes.
Estas variables son:
- Demanda
- Lead Time
- Variación de la demanda
- Variación del Lead Time
- Nivel de Servicio
DEMANDA
Solo el hecho de comercializar un producto y de atender la demanda en el momento correcto y en la cantidad correcta (principios de la Logística empresarial) hace que debamos mantener inventario, de no mantener inventario disponible, la competencia podría sacar ventaja y podemos perder participación de mercado.
La generación de inventario deberá ser proporcional al nivel de demanda entre más alta la demanda así deberá ser los niveles de inventarios (ya lo explicamos anteriormente que depende de la clase de empresa y de producto).
VARIACION DE LA DEMANDA
Si la demanda fuera constante conoceríamos con alto grado de certeza cuanto inventario adquirir y nos anticiparíamos de una manera segura, lamentablemente como ocurre con la demanda de muchos productos esta presenta variaciones periodo a periodo, esta variación de la demanda genera algún grado de incertidumbre y ante una demanda con incertidumbre debemos subir los niveles de inventario con el fin de cubrir las variaciones.
LEAD TIME
Conocido como el tiempo de reaprovisionamiento, lo podríamos definir como el tiempo que transcurre desde que se genera la orden de compra hasta que se entrega al cliente, en este lapso la cadena de suministro se encuentra en su periodo más vulnerable debido a que sus existencias de inventario se encuentran en niveles bajos y las ordenes emitidas aun no son entregadas.
Los niveles de inventarios deberán ser proporcionales al tiempo de reaprovisionamiento para garantizar la continuidad del suministro, entre mayor sea el Lead Time mayor deben ser los niveles de inventario.
Ejemplo: si la compañía cuenta con un proveedor a nivel nacional donde el tiempo de entrega de una orden es de 15 días, esta compañía deberá contar con inventario suficiente para operar con tranquilidad durante estos 15 días.
VARIACIÓN DEL LEAD TIME
La variación en los tiempos de reaprovisionamiento es normal dentro del flujo de la cadena de abastecimiento, estos se presentan por situaciones durante el transporte de la mercancía hacia el cliente, también porque el proveedor del proveedor tarda mas tiempo en entregarle sus mercancías, entre otras más situaciones.
Cuando la variación del Lead Time es alta puede resultar como el peor panorama que puede tener la cadena de abastecimiento debido a que los cálculos del aprovisionamiento se hacen partiendo del tiempo estándar definido en la negociación con los proveedores, entre mayor sea la variación del Lead Time mayor deben ser los niveles de inventario.
NIVEL DE SERVICIO
El nivel de servicio representa la probabilidad esperada de no llegar a una situación de falta de existencias. Este porcentaje es necesario para calcular el inventario de seguridad, a mayor nivel de servicio mayor será el nivel del inventario de seguridad, de esta manera, si el nivel de servicio de una determinada referencia es del 90%, esto significa que existe una probabilidad del 90% en la atención de la demanda o, dicho de otro modo, que teóricamente 90 de cada 100 clientes verán satisfecha su demanda en los tiempos previstos.
GENERADOR ANTINATURAL
Los GENERADORES ANTINATURALES de inventarios son aquellas variables, aspectos o procesos dentro de la cadena de suministro que intervienen de manera negativa en los niveles de inventarios.
Es en este aspecto donde se debe prestar mayor atención por parte de los planeadores de abastecimiento para disminuir su impacto, entre los generadores antinaturales de inventarios encontramos:
- Tamaño del lote de fabricación
- Tamaño mínimo de compra (economía de escala)
- Overfitting (sesgo negativo del error de pronóstico)
- Capacidad instalada (producción y almacenamiento)
- Incertidumbre en el abastecimiento
TAMAÑO MINIMO DE LOTE DE FABRICACIÓN
Para optimizar costos de fabricación por unidad producida las empresas están haciendo grandes inversiones en maquinaria y equipos con la finalidad de producir grandes volúmenes de producto al menor costo.
Lamentablemente estos volúmenes de fabricación no van en línea con la demanda de productos clase C, casi siempre el volumen producido es mayor de lo que el mercado demanda en estos artículos.
TAMAÑO MINIMO DE COMPRA
Al igual que el punto anterior, las fuentes proveedoras no son ajenas a la optimización de sus procesos productivos, las economías de escala están generando en las empresas compras más eficientes en costo, pero no están teniendo en cuenta que, a mayor volumen de producto negociado y adquirido, mayor es el proceso logístico de recibo, almacenamiento y administración.
En ocasiones estos lotes mínimos de compra son generadores de niveles de inventario adicionales a los requeridos por la organización.
OVERFITTING
También conocido como el sesgo negativo del error de pronóstico, ocasionado por un proceso repetitivo de planeación muy optimista, sobrestimando la demanda, en la medida que los pronósticos de demanda superen a la demanda real durante 2 periodos consecutivos o más esto terminará reflejado en excesos de inventarios.
CAPACIDAD INSTALADA
Se hace énfasis tanto a los centros de almacenamiento como a las líneas de fabricación, ambos departamentos cuentan dentro de sus indicadores con el costo por unidad (producida y almacenada), entre mayor sea el numero producido y almacenado menor serán los costos por unidad.
También se ha demostrado que ha mayor espacio de almacenamiento existe una vaga necesidad de querer llenar ese espacio, este proceso en ocasiones demanda al proceso de fabricación una mayor entrega de producto para beneficio de ambas partes.
INCERTIDUMBRE EN EL ABASTECIMIENTO
En ocasiones se presentan situaciones externas que podrían afectar la continuidad del suministro, situaciones como un paro de transporte, de trabajadores, huelgas, escases de materias primas o un posible aumento de su costo hace que los encargados de abastecimiento anticipen el inventario necesario hasta que consideren que no habrá afectación en la disponibilidad.
Acerca de JOSÉ ANDRÉS ROSAS
correo electroníco: joserosassoluciones@hotmail.com

INDICADORES DE PRECISIÓN DE PRONÓSTICOS
Importancia de los pronósticos de demanda
Si tuviéramos que elegir un indicador dentro de los KPI´s de la organización ese sería el de precisión de los pronósticos de demanda. Mientras más cerca el pronóstico esté de la realidad, más cerca estaremos de evitar situaciones como: sobrestock, quiebres de stock, pérdidas de venta y altos costos logísticos, entre otros efectos. De hecho, el indicador de precisión de los pronósticos debería ocupar los primeros lugares en la jerarquía de los indicadores de Logística y Supply Chain.
Además, un buen pronóstico de demanda tiene un buen efecto financiero, se puede simular que, para productos de alta rotación con un EBIT de 5% y un nivel de servicio de 97%, una mejora de 10% en este índice puede aportar un 4% de rentabilidad. Cuando hay economías de escala y largos tiempos de abastecimiento, la precisión de los pronósticos es especialmente crítica. Dice David J. Closs en su libro ADMINISTRACIÓN Y LOGISTICA EN LA CADENA DE SUMINISTRO “en este caso es fundamental una predicción precisa, porque es necesario predecir un período extenso en el futuro para permitir economías en la producción o en el transporte”.
Que es la precisión de pronóstico de demanda
Antes de todo, debemos aceptar que los modelos de pronósticos siempre van a presentar desviaciones (bias) respecto a la demanda real, el éxito de un buen proceso de estimación radica en la destreza y habilidad de la persona encargada de ejecutar el proceso de estimación, al momento de seleccionar el mejor modelo y de escoger el mejor resultado.
Pero el resultado de la precisión es relativo; esto es algo específico de cada contexto. Para una compañía eléctrica, el pronosticar el consumo de energía nacional para el día siguiente en un país latinoamericano, una precisión del 95 % en la estimación es considerado relativamente impreciso; mientras que lograr una precisión cercana al 70 % a nivel de tienda en el primer mes de ventas de un producto nuevo se considera un logro significativo.
La precisión de pronóstico de demanda no es más que el grado de aproximación existente entre el valor real y el valor pronosticado, su cálculo y adecuada interpretación nos permite tomar decisiones frente a cuál modelo de pronóstico presenta mejor desempeño o cual modelo de pronóstico logra interpretar mejor los patrones de comportamiento de la demanda.
Factores que afectan la precisión de pronóstico
Existen dos tipos de desviaciones de pronósticos:
- Desviaciones Sistemáticas: Son ocasionadas por una desviación constante, como una mala interpretación de los componentes de la demanda como tendencia, continuidad, estacionalidad, usar variables incorrectas o relaciones equivocadas. También es ocasionada por eventos o promociones activadas por mercadeo y que no fueron anunciados al área de planeación. Este tipo de desviación se minimiza con la capacitación, la comunicación y el tiempo de experiencia del administrador de pronósticos.
- Desviaciones Aleatorias: Es aquella desviación que no tiene explicación, es decir, que fue originada por factores imprevisibles y por ende no se conoce la causa.
¿Cuántas medidas de precisión existen, cual es la mejor y cómo aplicar cada una de ellas?
Para cada uno de los escenarios que usted genere es necesario medir el desempeño en cada observación, en cada evento presentado o en cada periodo.
Se requiere definir un criterio para la precisión del pronóstico (datos de predicción) y otra para la selección del modelo (datos de control). No todos tendrán el mismo significado ni uso.
Comenzaré explicando los indicadores que miden el desempeño del pronóstico en cada periodo de tiempo t y después explicaré los indicadores que miden el desempeño del proceso de estimación en N periodos.
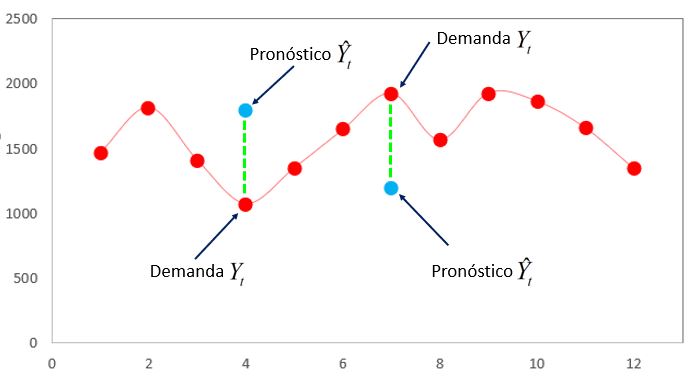
Error de periodo
También conocida como desviación de la observación o de evento (et), es la fórmula más básica del proceso de estimación, de ella derivan gran parte de los indicadores de precisión.
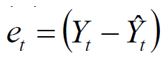
Yt representa la demanda real y Ŷt representa el valor de pronóstico, la desviación entre estas dos variables da como resultado un valor dimensional, puede ser tanto positivo como negativo e indica el valor de desviación entre la demanda y el pronóstico en el periodo t.
Error absoluto de periodo
Mide la desviación en valor nominal o la magnitud entre el valor de la demanda y el valor del pronóstico en el periodo t.
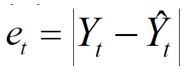
Este indicador busca evitar el fenómeno que ocurre con el indicador anterior (desviación de periodo) al momento de promediar o sumar desviaciones dado que valores negativos y positivos se netean, con este indicador de desviación absoluta el resultado global al momento de acumular las deviaciones absolutas de N periodos su resultado será un valor nominal positivo.
Error cuadrático de periodo
Mide la desviación en valor nominal entre el valor de la demanda y el valor del pronóstico, pero elevada al cuadrado en el periodo t.
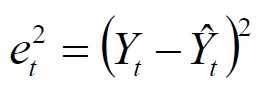
Tiene la misma propiedad que el indicador anterior, solo que este indicador castiga los periodos con altas desviaciones elevándola al cuadrado (alejando al pronóstico del objetivo que es estar cercano a cero).
% del Error de periodo
Es la manifestación de un error relativo en términos porcentuales entre la observación real (demanda) y el pronóstico en el periodo t.
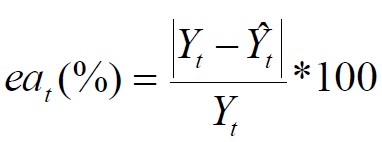
El hecho que se estime una magnitud del error porcentual lo hace un indicador frecuentemente utilizado por los planeadores debido a su fácil interpretación.
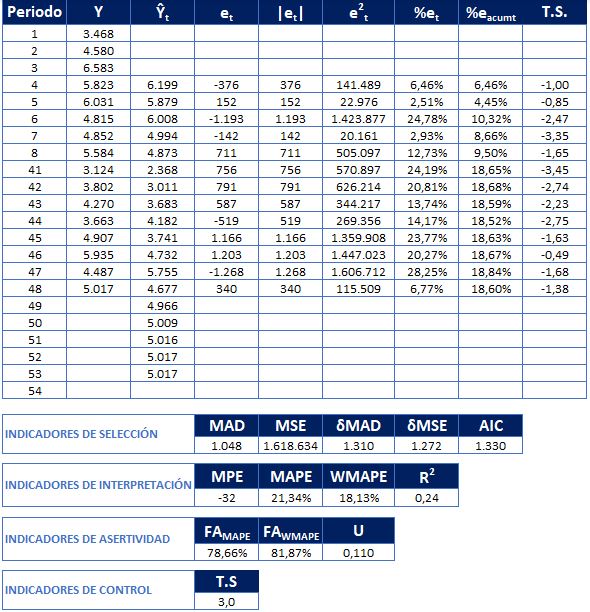
En el cuadro 1. Podemos observar la aplicación de los 4 indicadores de precisión de un pronóstico de demanda para el periodo 4, se presenta una serie de tiempo de 4 periodos, los periodos del 1 al 3 se usan como procedimiento de inicialización para pronosticar el periodo 4, donde Y4 representa la demanda real y Ŷ4 representa el valor de pronóstico.
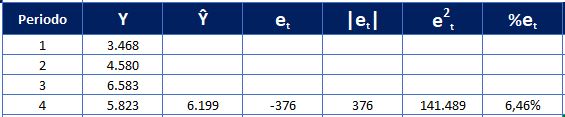
A continuación, revisaremos y analizaremos los indicadores de precisión que miden el desempeño del proceso de estimación para N periodos. En esta parte del articulo haremos referencia a las 4 familias de indicadores de precisión, estos son:
Indicadores de Selección
Indicadores de Interpretación
Indicadores de Asertividad
Indicadores de Control
Indicadores de Selección
Como su nombre lo indica son los indicadores que sirven para seleccionar un modelo de pronóstico que presente el error mínimo entre las observaciones de N periodos, en otras palabras, hacer match entre modelo – serie de tiempo, en este grupo se encuentran los siguientes:
MAD (Mean Absolute Desviation)
Representa la desviación promedio del pronóstico en valores absolutos. Mide la dispersión entre los valores de la demanda y los valores del pronóstico.
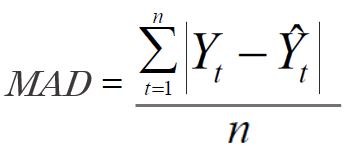
Se obtiene tomando el promedio de las observaciones del indicador número 2, mediante el valor absoluto de las diferencias entre la demanda real y la pronosticada, dividida entre la cantidad de errores.
δMAD Desviación del MAD
Cuando las desviaciones de un pronóstico de demanda se aproximan a una distribución normal (que es el caso más común), entonces la Desviación Absoluta Media o MAD se relaciona con la desviación estándar (σ) como: 1δ≅1,25MAD.
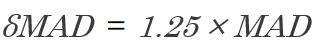
Si los límites de control (tema tratado más adelante) se establecen en ±3 desviaciones estándar (aproximadamente 3,75 MAD), entonces el 99,7% de las desviaciones caerían dentro de estos límites.
La δMAD es ideal para calcular inventarios de seguridad (S.S) dado que toma las deviaciones del pronóstico de demanda y no la desviación de la demanda.
MSE (Mean Square Error)
Es el promedio de los cuadrados de las desviaciones de la estimación en los N periodos.
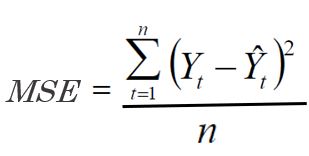
Los resultados son valores poco entendibles dentro del proceso de estimación debido a que las desviaciones son elevadas al cuadrado, en ocasiones son valores de 6, 7 y hasta más dígitos, como se mencionó en el indicador número 3 el objetivo de este indicador es castigar los modelos con alto nivel de desviación (para irlos descartando) alejándolos del objetivo de acercarse al cero.
RMSE (Root Mean Square Error)
Es la raíz del promedio de los cuadrados de las diferencias de la estimación en los N periodos, es uno de los indicadores de precisión más confiables para comparar los diferentes métodos o criterios de pronóstico.
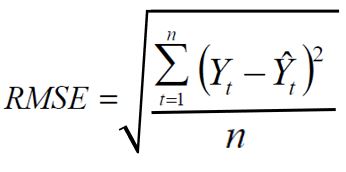
También es conocido como la desviación del error cuadrático con la expresión δMSE ó raíz del MSE , esta medida junto con la desviación del MAD son los indicadores más recomendados para (hacer match) seleccionar el mejor modelo de pronóstico, pero a pesar su efectividad probada ésta no es muy utilizada entre los planeadores.
AIC (Akaike Information Criterion)
Esta herramienta penaliza la complejidad del modelo tomando en cuenta el número de variables y se utiliza para seleccionar el mejor modelo dentro del conjunto de los mismos datos. Los métodos de Box & Jenkins tiene esta característica, ya que utilizan valores reales y anteriores de la variable independiente para producir pronósticos precisos a corto plazo.
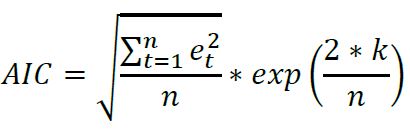
Durante el proceso de match se escoge el modelo que presente menor valor de AIC, la variable K representa el numero de variables analizadas, en planeación de demanda, entendemos que el proceso de estimación es univariable (demanda histórica) lo que hace que K tome el valor de 1, es poco usado por los profesionales de planeación.
Indicadores de Interpretación
Las medidas de interpretación buscan darle al planeador de demanda herramientas de juicio sobre el desempeño del modelo de pronóstico, no son ideales para la selección de un modelo cuando se comparan los resultados de varios modelos, el resultado de estos indicadores nos muestran si el modelo tiene o no tiene una aceptable desviación a nivel porcentual (de acuerdo a las políticas del área de planeación), pero este resultado no indica si es el modelo óptimo para esa serie de tiempo.
MPE (Mean Percentage Error)
Es una métrica simple, sirve para mostrarnos si la desviación del pronóstico presenta sesgo positivo o negativo, también se dice que el pronóstico está optimista o conservador.
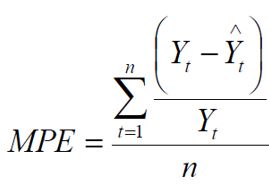
Hay que recordar que como planeadores debemos evitar mantenernos varios periodos consecutivos subestimando (underfitting) o sobrestimando (overfitting), la primera generaría ruptura de stock y la segunda excesos de inventarios. Su resultado pueden ir desde -100% hasta +100% y cuando un modelo de pronóstico exhibe un MPE consistentemente alejado de cero o periódicamente mantiene el sesgo (positivo o negativo) debe evaluarse la necesidad de replantearlo pues el modelo puede estar peligrosamente sesgado.
MAPE (Mean Absolute Percentage Error)
Mide la magnitud del error en valor porcentual, no considera el signo del error. El MAPE es una de las medidas más utilizadas a nivel mundial, no es recomendable para la selección de un modelo puesto que presenta sesgos que favorece a los pronósticos que están por debajo de los valores reales.
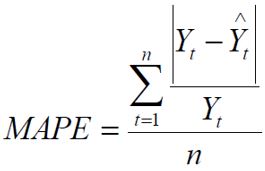
El hecho que se estime una magnitud de la desviación porcentual lo hace un indicador frecuentemente utilizado por los encargados de elaborar pronósticos debido a su fácil interpretación, incluso es útil cuando no se conoce o no se tiene a la mano el volumen de demanda del producto dado que es una medida relativa. Por ejemplo, afirmar que la “desviación porcentual promedio es un 10%” es más fácil de comprender que cuando se dice “la desviación absoluta media por período es de 5.600 unidades”
WMAPE (Weighted Mean Absolute Percentage Error)
Es el MAPE ponderado por el peso de la demanda. Es un indicador muy recomendado ya que la ponderación del total minimiza los efectos de productos con demanda muy variable, pero con poco impacto en los valores reales, al igual que el MAPE presenta sesgos que favorece a los pronósticos que están por debajo de los valores reales.
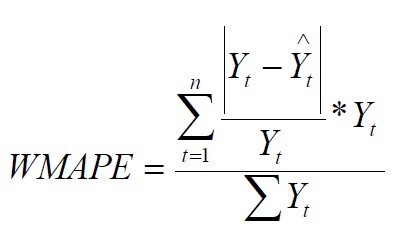
R2 Coeficiente de Determinación
Este coeficiente determina la calidad del modelo para interpretar los resultados y la proporción de variación de los resultados que puede explicarse por el modelo. El resultado del coeficiente de determinación oscila entre 0 y 1. Cuanto más cerca de 1 se sitúe su valor, mayor será el ajuste del modelo a la variable que estamos intentando explicar.
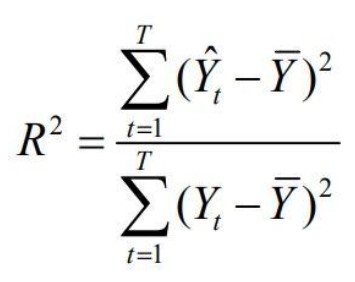
Indicadores de Asertividad
Las medidas de asertividad buscan probar que tan efectivo fue el modelo o los modelos seleccionados para pronosticar, en seguida se muestran varias alternativas para evaluar la efectividad del modelo seleccionado para pronosticar tales como el FA (forecast accuracy) y el coeficiente U de Theil. La selección dependerá siempre de los resultados esperados en la organización y de la experiencia del planeador.
FA (Forecast Accuracy)
La forma más común de medir la asertividad de un pronóstico es comparar los resultados del pronóstico contra los valores reales, si sabemos de antemano que el pronóstico va a presentar un nivel de desviación (ver el vaso medio vacío), porque no presentar la información con el lado bueno del desempeño del modelo (ver el vaso medio lleno). El objetivo es encontrar valores cercanos a 1 para emitir juicios favorables sobre el modelo de pronóstico seleccionado.
Si el MAPE o WMAPE representa el vaso medio vacío, (1- MAPE) ó (1-WMAPE) representará el Forecast Accuracy ósea el vaso medio lleno.
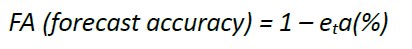
U de Tehil
Es un indicador econométrico, el coeficiente de desigualdad U de Theil es otra medida que permite analizar la efectividad del modelo seleccionado en la predicción. Recordemos que las medidas de desviaciones absolutas en lugar de las desviaciones cuadráticas suelen presentar sesgos y éstos últimos penalizan en mayor medida las altas desviaciones. La elección dependerá de la importancia que se les dé a las altas desviaciones. El coeficiente de desigualdad U de Theil presenta una solución para estos escenarios.
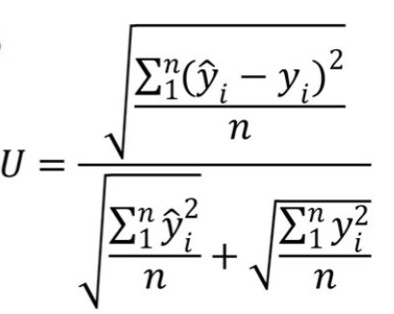
Si el U de Theil es cercano a cero, entonces nos indicaría que el modelo realiza una buena predicción, pero si analizamos los componentes del Theil como el sesgo si no tiende a cero, la varianza es pequeña y la covarianza no es muy alta se puede concluir que el modelo de estimación no es efectivo, es poco usado por los profesionales de planeación.
Indicadores de control
Las medidas de control ayudan en suministrar información al planeador acerca de la estabilidad del pronóstico, un modelo de pronóstico estable indica que su resultado es confiable, el planeador puede encontrarse con indicadores de interpretación de bajos resultados, pero con una buena señal de rastreo, se considera un modelo estable aquel que la acumulación de sus desviaciones se encuentra dentro de las ±3 desviaciones estandar. Un indicador que nos muestra lo expresado anteriormente es la señal de rastreo o tracking signal.
T.S. (Señal de Rastreo)
Es una medida de control que permite medir la desviación del pronóstico respecto a variaciones en la demanda. Análogamente se puede interpretar como el número de MADs (Desviación Media Absoluta o Mean Absolute Deviation) que el pronóstico está sobrestimado o subestimado.
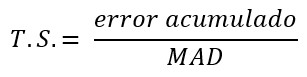
Si los límites de control se establecen en más o menos 3 desviaciones estándar (aproximadamente 3,75 MAD), entonces el 99,7% de los puntos caerían dentro de estos límites, entonces podemos decir que el modelo de pronóstico se encuentra estable.
A continuación presentamos un ejemplo en el cuadro 2 de la implementación de los indicadores de precisión de pronósticos.